WRInaute discret
Bonjour à tous,
Je reçois régulièrement des alertes dans GSC concernant certaines pages web du site non indexées.
J'ai par exemple 232 pages non indexées avec redirection.
La 1/2 moitié concerne des pages en http qui sont passées depuis au moins 3 ans en https. Mais google continue à les crawler.
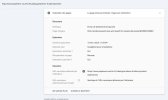
Ex dans la GSC :
1) http://www.pepiniere-courtin.fr/realisations/bassins-de-jardin/ et la même en https : https://www.pepiniere-courtin.fr/realisations/bassins-de-jardin/
ou
un autre exemple :
http://www.pepiniere-courtin.fr/catalogue/rosiers/rosiers-buissons et la même en https : https://www.pepiniere-courtin.fr/catalogue/rosiers/rosiers-buissons
Que faire pour enlever ces pages en http (si on peut le faire bien sûr) ?
Merci.
Cordialement,
Je reçois régulièrement des alertes dans GSC concernant certaines pages web du site non indexées.
J'ai par exemple 232 pages non indexées avec redirection.
La 1/2 moitié concerne des pages en http qui sont passées depuis au moins 3 ans en https. Mais google continue à les crawler.
Ex dans la GSC :
1) http://www.pepiniere-courtin.fr/realisations/bassins-de-jardin/ et la même en https : https://www.pepiniere-courtin.fr/realisations/bassins-de-jardin/
ou
un autre exemple :
http://www.pepiniere-courtin.fr/catalogue/rosiers/rosiers-buissons et la même en https : https://www.pepiniere-courtin.fr/catalogue/rosiers/rosiers-buissons
Que faire pour enlever ces pages en http (si on peut le faire bien sûr) ?
Merci.
Cordialement,

")




