
Voici le résumé officiel :
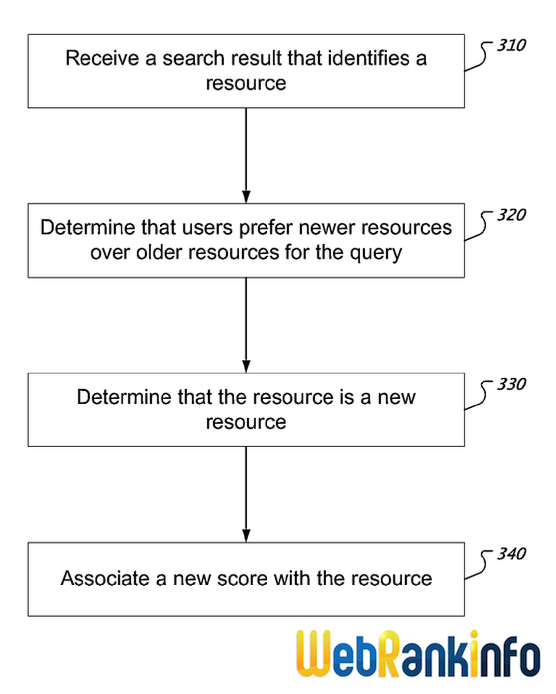
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for ranking search results. One of the methods includes receiving a search result obtained in response to a query, wherein the search result identifies a resource and has an associated score S. A determination is made that users prefer newer resources over older resources for the query and that the resource is a new resource. A new score S' is associated with the resource in place of S, based on the determination that users prefer newer resources over older resources for the query and that the resource is a new resource.
En gros, l'idée générale est très simple : quand le système identifie que la requête de l'internaute nécessite "de la fraîcheur", les pages avec des contenus créés récemment sont favorisées dans les résultats. C'est le principe Query Deserves Freshness (QDF) bien connu depuis des années par les référenceurs (au moins 2011 avec l'officialisation par Google). Mais ici on a droit à un brevet, alors autant y jeter un coupe d'oeil !
Comment Google peut-il détecter que l'internaute cherche des documents récents ?
Le brevet indique que c'est quand la requête est d'un "intérêt particulièrement récent". Pour le déterminer, le système se base notamment sur les éléments suivants :
- le nombre d'occurrences de cette requête pendant une période récente dépasse un certain seuil
- le nombre d'occurrences de cette requête sur des articles de blogs pendant une période récente dépasse un certain seuil
- le nombre d'occurrences de cette requête sur des articles d'actualité pendant une période récente dépasse un certain seuil
- le nombre d'occurrences de cette requête sur des publications de réseaux sociaux pendant une période récente dépasse un certain seuil
- le nombre d'occurrences de cette requête nécessitant des résultats d'actualité pendant une période récente dépasse un certain seuil
- le ratio entre {le nombre d'occurrences de cette requête nécessitant des résultats d'actualité pendant une période récente} et {le nombre d'occurrences de cette requête nécessitant des résultats web pendant la période} dépasse un certain seuil
- le nombre de clics des internautes sur des résultats d'actualité pendant une période récente dépasse un certain seuil
- le ratio entre {le nombre de clics des internautes sur des résultats d'actualité pendant une période récente} et {le nombre de clics des internautes sur des résultats web pendant la période} dépasse un certain seuil
Le système calcule :
- une valeur Q pour la requête basée sur la valeur maximale d'un ou plusieurs indicateurs de fraîcheur
- une valeur D pour chaque ressource (page web) basée sur son âge, avec une valeur décroissante de façon monotone en fonction de l'âge (fonction sigmoïde inverse). Un facteur lié à la qualité de la ressource modifie la valeur de D. Ce score de qualité est composé d'une note indépendante de la requête, d'une autre dépendante de la requête, et d'une autre qui évalue à quel point la ressource correspond à la requête
- le score S' de la ressource (c'est-à-dire son positionnement) est calculé en faisant le produit de son score initial S par une fonction de boost dépendant de Q et D
- la fonction de boost peut renvoyer un score inférieur ou supérieur à 1 (donc elle améliore ou dégrade le positionnement), calculé sous la forme QD
Voici le schéma général du brevet :
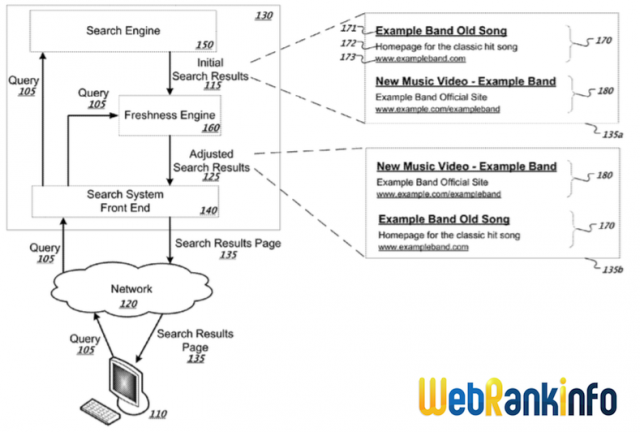
Les principaux modules :
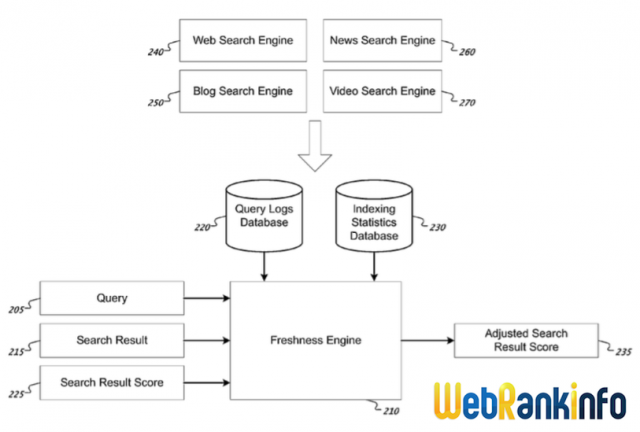
Synoptique :
Références du brevet : "Freshness based ranking" inventé par Zhihui Chen et Jonathan Frankle déposé le 15/03/2013 et obtenu le 17/11/2015 sous le n°9,189,526 USPTO.
Source : USPTO
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.
➡️ Offre MyRankingMetrics ⬅️
pré-audit SEO gratuit avec RM Tech (+ avis d'expert)
coaching offert aux clients (avec Olivier Duffez ou Fabien Faceries)
Voir les détails ici


Laisser un commentaire