
Je ne vais pas décrire le fonctionnement complet du fichier robots.txt, si besoin lisez cet article.
En résumé, par défaut les robots des moteurs de recherche s'autorisent à crawler ("explorer") toutes les URL. Si vous souhaitez leur interdire certaines pages ou rubriques de votre site, il faut ajouter des directives dans le fichier robots.txt.
La syntaxe est définie sur robotstxt.org mais sachez que certains moteurs prennent en compte des instructions spécifiques. Par exemple Googlebot tient compte des caractères * et $ ainsi que de la directive Allow, et de son côté Bing tient compte de Crawl-delay. Il ne s'agit que de quelques exemples non exhaustifs.
Une erreur dans un fichier robots.txt peut avoir des conséquences importantes sur votre référencement. Vous ne risquez pas de faire désindexer des pages (pour cela il faut la balise meta robots noindex), mais de bloquer le crawl des nouvelles pages.
Pour ne pas vous tromper, le mieux est de faire des tests !
Pour ça, je vous recommande de suivre mon tuto :
Retrouvez ce tuto de test du fichier robots.txt sur YouTube
Explications :
- Allez sur https://www.google.com/webmasters/tools/robots-testing-tool?hl=fr)
- Google indique le contenu du fichier robots.txt tel qu'il l'a vu la dernière fois (ou alors rien du tout si vous n'en avez pas)
- Si jamais vous avez un fichier robots.txt non vide, sélectionnez tout et supprimez
- Copiez-collez le contenu du fichier robots.txt à tester (ça peut être votre fichier à tester, ou celui d'un client, ou d'un concurrent)
- Tapez ensuite l'URI de la page à tester (c'est-à-dire la partie de l'URL qui suit votre nom de domaine, sans mettre le / de la racine qui est déjà inclus)
- Cliquez sur Tester
Google vous indique le résultat :
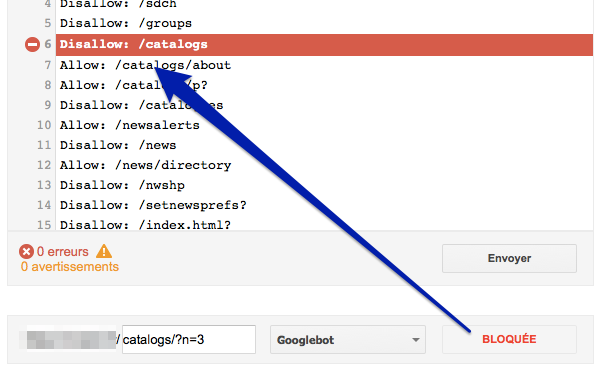
- Si l'URL est interdite au crawl, Google affiche "Bloquée" et surligne en rouge la ligne qui bloque le crawl
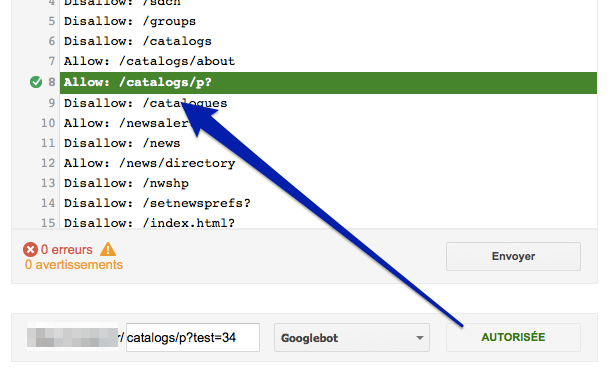
- Sinon, Google affiche "Autorisée". Si jamais c'est en raison d'une ligne particulière, elle est surlignée en vert.
Exemple d'URL bloquée :
Exemple d'URL autorisée :
Rappelez-vous qu'il faut tester aussi pour d'autres robots que ceux de Google (Bingbot et les autres).
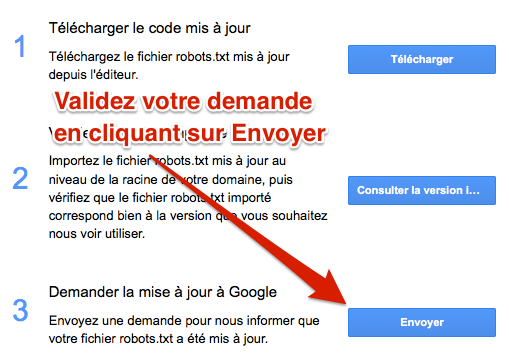
Une fois que vous avez validé que votre fichier robots.txt est correct, n'oubliez pas de l'uploader sur votre serveur !
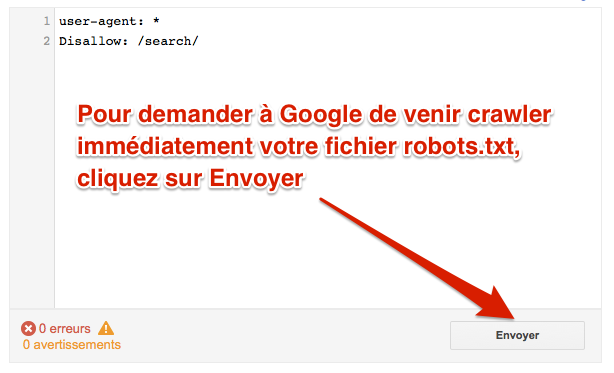
Si jamais votre fichier robots.txt a changé et que vous souhaitez que Google vienne le crawler rapidement, cliquez sur Envoyer :
Puis, une fois que vous avez bien vérifié que votre fichier en ligne est OK, cliquez à nouveau sur Envoyer afin que Googlebot vienne le consulter et en tenir compte au plus vite :
En préparant ce dossier et ce tutoriel, j'ai remarqué que Google tient compte de la directive "Disalow" (écrite avec un seul L)...
Des questions ? Posez-les en commentaires !
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.

Bonjour ,
j'ai un fichier bloqué : Disallow: /app/
est ce grave ?? est ce que je peu y remedier ?
Salutations Fabien
si /app/ a besoin d'être bloqué ce n'est pas gênant, sinon il suffit de retirer la ligne (pour éditer ce fichier, demandez à celui qui vous a fait le site)
bonjour, je veux ajouter une nouvelle page web au Site maps pour suivre son référencement mais j'arrive pas à ajouter l'URL à la liste des URL que j'avais
@ Haydi : il faut utiliser un outil qui génère automatiquement le sitemap, ça ne doit pas se gérer manuellement...