
Fonctionnement
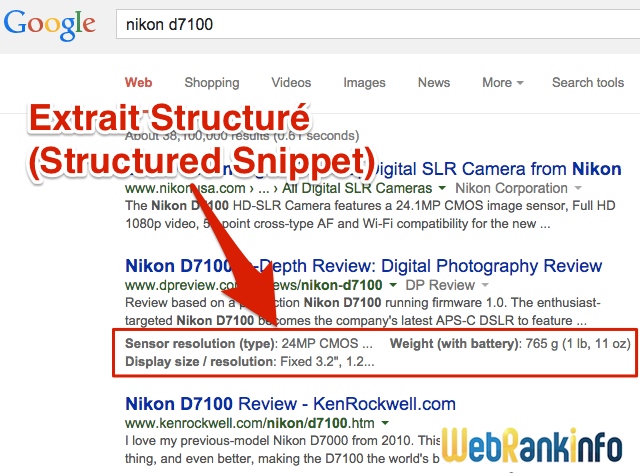
D'après les informations fournies par Google, l'objectif est de regrouper sous le descriptif classique un certain nombre de faits correspondant précisément à la page. Concrètement, testez l'exemple fourni par Google, repris dans la capture d'écran ci-dessus : la requête [nikon d7100].
Un algorithme analyse le contenu des pages pour les identifier, notamment les tableaux inclus dans les pages HTML. Si les données extraites passent les contrôles de qualité (automatisés), alors elles peuvent être affichées sous forme d'extrait structuré.
Schema.org non utilisé, le machine learning à la rescousse
Notez que, pour une fois, cet algorithme n'exploite pas les données structurées au format schema.org. Cet algorithme a été mis au point par l'équipe WebTables de Google Research, incluant sans doute les auteurs de l'annonce officielle, à savoir Corinna Cortes, Boulos Harb, Afshin Rostamizadeh, Ken Wilder et Cong Yu. Comme vous l'avez deviné par son nom, cet algo s'intéresse aux données tabulées (dit autrement, les tableaux, balise <table>). Un système d'apprentissage automatique (utilisé partout chez Google, de Panda à Pingouin en passant par la recherche de liens artificiels) sait ignorer les tableaux sans intérêt, par exemple ceux utilisés (à tord) pour le design des pages. La dernière partie de l'algorithme sélectionne au maximum 4 faits les plus pertinents pour enrichir le résultat présenté à l'internaute.
Dans les SERP sur ordinateur, les 4 données du Structured Snippet sont souvent affichées en 2 colonnes de 2 lignes, tandis que sur mobile tout est sur une seule colonne. Mais parfois Google affiche ces données sous forme de tableau, comme dans cet exemple :

Voilà en tout cas une preuve de plus que Google fonctionne désormais comme un moteur de recherche sémantique (ce qui a été révélé assez officiellement avec l'update Colibri). Le fait que Google ait décidé de ne pas se baser sur les données structurées "standard" (type schema.org) me semble aller dans le même sens que l'abandon des balises de l'authorship. A mon avis, Google a considéré que le nombre de sites avec des données schema.org était trop faible pour se baser uniquement sur ça.
Comment bénéficier des Structured Snippets pour son site ?
Pour l'instant on n'en sait pas assez pour répondre, mais il me semble qu'il faut réunir les conditions suivantes :
- une page ayant un bon niveau de qualité, pertinente pour la requête
- des données tabulées intégrées de façon simple à extraire sans erreur
- un bon score d'expertise et d'autorité de la page et/ou du site pour le sujet concerné
Pensez-vous à d'autres critères ? Quel est votre avis ?
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.
➡️ Offre MyRankingMetrics ⬅️
pré-audit SEO gratuit avec RM Tech (+ avis d'expert)
coaching offert aux clients (avec Olivier Duffez ou Fabien Faceries)
Voir les détails ici


Merci pour ces réponses. Mais justement, à ma connaissance, le rich snippet dont on connait habituellement puise ses donnnées dans le schema.org selon le balisage que l'on a mis en place. Et dans l'article, ça dit que le structured snippet n'exploite plus ces anciennes données structurées. D'où ma question, est-ce que plus tard, cela ne servira plus à grand chose de mettre en place le schema.org ? Car finalement, ce sera l'algorithme relatif au structured snippet qui primera ?
Le rich snippet est créé à partir des informations récoltées par Google, en partie grâce à des données structurées, dont celles au format schema.org. Bref, le structured snippet n'est qu'un sous-ensemble des rich snippets et ne remet pas en cause les données structurées.
Dites, est-ce du coup le structured snippet remplacera le rich snippet donc ? ou est-ce que ça va cohabiter dans les résultats de recherche ? C'est dommage si le rich snippet va disparaitre, je ne l'ai mis en place qu'il y a quelques mois.
Le structured snippet fait partie de ce qu'on appelle un rich snippet. Un snippet est un extrait qui donne des informations sur un résultat ; l'extrait standard est constitué de lignes de texte brut, tandis que l'extrait enrichi contient d'autres éléments (étoiles pour les avis, nom d'une personne, prix, date d'un événement, photo d'une recette, vignette d'une vidéo, données factuelles, etc.).
J'ai constaté également l'ajout pour certains site de barre de recherche interne au site recherché (par exemple la recherche web rank info, renvoi en dessous de l'affichage du lien une barre de recherche interne)
Cela fait aussi partit des test en cours ?
@Fred : cette barre de recherche interne dans les SERP est nouvelle en effet. Je t'invite à lire mon article sur le sujet
Je trouve ça super en tant qu'utilisatrice, mais dommage en tant que "petit" du web.
Les balises schema.org, ça fait un moment que je les ai mises sur mon site... Et pour rien, donc, semble-t-il... Puisque Môssieur GG ne s'en sert pas, et n'affiche de toute manière ce genre d'info que sur les gros sites...
Donc quand on est sur une niche, on peut toujours attendre un moment avant de profiter de ce genre d'avantages... même si on s'enquiquine à suivre les actus GG et à appliquer à la lettre toutes les nouveautés...
@Angie : Google indique que pour ces extraits structurés, ils n'utilisent pas les données structurées type schema.org. Mais ces dernières sont exploitées par ailleurs, quelle que soit la taille du site. Ce qui est déconcertant par contre, c'est que dans la grande majorité des cas, on n'a pas de preuve visible de leur utilisation par Google (et donc de leur intérêt).
C'est la tendance de Google de tout donner ou du moins le maximum d'informations sur le site, au point de se substituer de plus en plus à lui.
Je vois quand même le problème de ces données structurées en dehors des shémas usuels, et au final l'inutilité de ces dernières par conséquences.
Je ne vais pas aller contre Google en terme de résultat, il n'empèche que de mon point de vue, Google reste un moteur de recherche de site web, et en France, les entreprises qui n'ont pas site web sont encore quelques millions …