
Vous l'aviez déjà sans doute remarqué, parfois Google met en gras certains mots dans les résultats alors que vous ne les avez pas tapés dans votre requête. Il peut s'agir de synonymes ou d'autres types de relations entre les mots. Google l'avait d'ailleurs expliqué en 2010 sur le blog officiel.
Google vient de se voir accordé un brevet intitulé "Evaluation of substitute terms" dans lequel est décrit un système visant à substituer certains termes dans la requête de l'internaute. Mais au lieu de se baser uniquement sur des synonymes, Google cherche d'autres substituts dans les textes des résultats pour la requête initiale. Si un terme est présent dans la plupart de ces documents mais pas dans la requête de l'internaute (on parle donc de co-occurrence), alors Google évalue si c'est efficace de l'inclure dans la requête, en remplacement d'un autre.
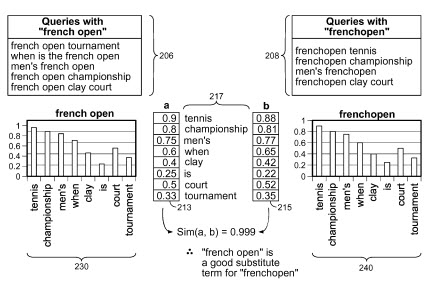
Pour une fois, on peut assez sérieusement pronostiquer que Google utilise déjà un tel système dans son moteur de recherche. Mais que faut-il en conclure quand aux techniques d'optimisation du référencement, particulièrement dans le travail éditorial ? Il me semble que cela devrait inciter à produire des contenus de qualité, avec un vrai travail de rédaction. Le rédacteur doit inclure (de façon spontanée ou pas) tous les mots et expressions que je pourrais appeler "sémantiquement proches" de l'expression-clé principale. Il doit même étendre cette analyse aux entités en lien avec le sujet principal de l'article, maintenant que Google est rompu à la détection des entités nommées.
Pour les habitués de WebRankInfo (et d'autres !), ceci n'est pas un scoop, cette approche est bien connue comme technique d'optimisation éditoriale du référencement : exactement le genre de choses que je détaille dans ma formation. Mais il y a encore tellement de gens qui ne se rendent pas compte à quel point l'optimisation éditoriale peut booster la visibilité Google et le trafic qualifié qui en découle !
Lisez le brevet Evaluation of substitute terms ou les explications de Bill Slawski
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.
➡️ Offre MyRankingMetrics ⬅️
pré-audit SEO gratuit avec RM Tech (+ avis d'expert)
coaching offert aux clients (avec Olivier Duffez ou Fabien Faceries)
Voir les détails ici


Bien vu et réellement sujet important pour le SEO tout aussi bien que la recherche vocale qui étend ctte notion un peu plus loin pour se concentrer sur des concepts plutôt que des mots. Oui la recherche sémantique est l'avenir de la recherche car la validation via les 3 graphes reste le seul moyen de contrer le spam : link graph, social graph, knowledge graph. J'avais même prédit en 2010 l'avénement du Marketing 3.0 avec la construction du Brand Character au lieu de slogans publicitaires et puis ma présentation 2011: http://slidesha.re/ppWwj0. J'aime particulièrement comment Bill Slawski décortique le sujet. Merci
Le gros problème c'est que la plupart des techniques SEO sont des exploitations abusives de principes de fonctionnement logiques de Google.
Privilégier le contenu est une très bonne chose, en ce qui me concerne je trouve que Google se dirige vers la bonne direction. Ils ne font que privilégier le respect du lecteur et c'est ce que tout bon "seoworker" devrait faire.
@Clovis : Certes, sauf que la plupart des référenceurs vont lire cet article en diagonale et ne retenir qu'une chose. Ils vont donc publier des articles bourrés de synonymes.
Et quand tu lis un article de 300 mots avec un champ lexical digne de l'Encyclopédie Universelle, tu es en droit de te demander où est le naturel ^^
En fait, le référencement naturel, c'est comme écrire français : tu t'appliques, tu fais de jolies tournures de phrases et tu évites les répétitions en utilisant des synonymes… ^^