
Voilà le résumé :
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for determining similarities between queries. A first query and a second query are identified, and first related queries associated with the first query and second related queries associated with the second query are also identified. One or more first features for the first query are identified, and one or more second features for the second query are also identified. A first score is calculated for each first feature based on the relatedness weight associated with the respective first related query including the term of the respective first feature, and a second score is calculated for each second feature based on the relatedness weight associated with the respective second related query including the term of the respective second feature. A similarity of the first query and the second query is determined based on the first score and the second score.
Ca vous parle, n'est-ce pas ? Voici mes explications, en espérant qu'elles soient justes et compréhensibles...
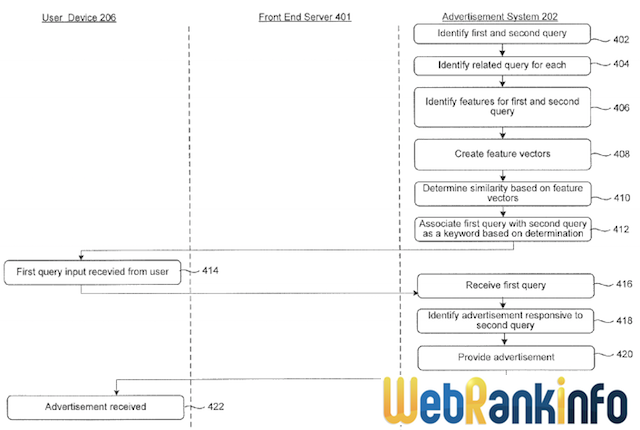
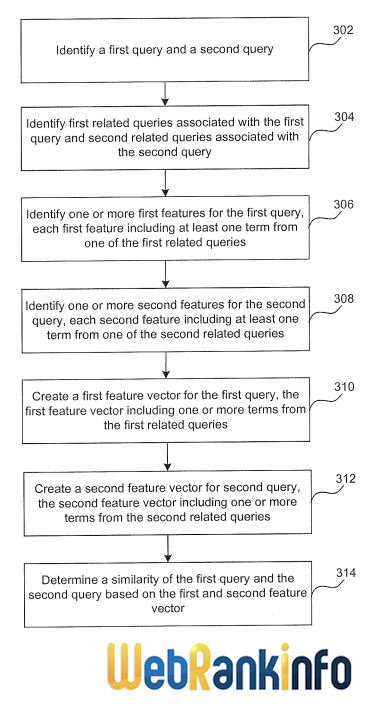
Le système cherche à évaluer la similarité entre les requêtes A et B. Il commence par récupérer une liste de requêtes A1, A2... An associées à la requête A, et une autre liste de requêtes B1, B2... Bn associées à la requête B. Des scores sont calculés pour ces requêtes associées en fonction de leur similitude avec la requête principale. Ensuite, ces scores sont stockés dans des vecteurs. Enfin, un calcul classique de similarité (fonction de similarité cosinus, ou Jaccard ou autre) entre ces vecteurs fournit un score de similarité entre les 2 requêtes.
Jusque-là, ça vous fait sans doute une belle jambe ! A quoi cela peut-il servir ? On peut imaginer que ça aide Google à créer ses suggestions de mots-clés (testez mon outil) ou peut-être ses recherches associées en bas de pages de SERP.
Mais en lisant les détails du brevet, j'ai vu qu'il peut y avoir un impact direct sur le référencement naturel. Ce n'est que mon interprétation, et ce n'est qu'un brevet (aucune preuve qu'il soit utilisé par Google) mais voici ce qui m'y fait penser...
L'inventeur explique ceci :
Once queries are identified as being similar, then one query can be used as a keyword for the other and potentially vice versa. For example, if query A is found to be similar to query B, then query A can be associated with query B a keyword and vice versa.
En d'autres termes, les requêtes similaires à celle tapée par l'internaute peuvent être utilisées en complément de celle-ci.
Therefore, when a query is received, for example query A, because it is associated with query B as a keyword, any advertisements found responsive to query B can be identified as a responsive advertisement for query A.
Ici on parle de l'impact sur les publicités, mais pourquoi ça ne serait pas également appliqué à la sélection de résultats ?
La suite :
In this example, the queries "car" and "motorcycle" were found to be similar 128. Therefore "car" can be a keyword associated with the query "motorcycle" and "motorcycle" can be a keyword associated with the query "car." If a user submits the query "car," because it is associated with the keyword "motorcycle," any advertisements associated with the keyword "motorcycle" can be found to be responsive to the original query "car."
En d'autres termes, si l'internaute cherche "voiture", le système peut identifier que "moto" est associé et donc afficher des publicités ciblées (aussi) sur "moto". Pourquoi ne pas imaginer que les résultats naturels de recherche ne seraient pas eu aussi déterminés à partir de "moto" en plus de "voiture" ? Ici les exemples choisis sont des termes relativement éloignés, mais s'ils sont plus proches, ça semble intéressant. Et dans ce cas les résultats affichés ne sont pas ceux pour la requête de l'internaute, mais pour une requête "complétée" (ce système est loin d'être nouveau, de nombreux brevets couvrent ce genre de choses).
Concernant la façon de trouver des requêtes similaires, il existe plusieurs travaux, notamment un autre brevet des mêmes inventeurs. Voici ce qu'ils indiquent :
One way of identifying related queries is the co-click technique. The co-click technique is described in U.S. patent application Ser. No. 12/632,363, entitled "Using Transition Probabilities to Expand Query Keywords to Trigger Advertisements," to inventors Diego Federici and Henrik Jacobsson, filed Dec. 7, 2009, which is herein incorporated by reference. Co-click works as follows. If a search result was responsive to a first query, and the search result was selected by a user, and the same search result was responsive to a second query and the search result was also selected by the user, the second query is a related query to the first query. In other words, the average user preference for a result can be estimated based on statistical analysis of the search logs. For example, if search result A was responsive to the query "cars for sale" and was selected by a user, and the search result A was also responsive to the query "used cars" and "vintage cars," and both times the search result A was selected by the user, then "used cars" and "vintage cars" can be related queries for the query "cars for sale."
En résumé, une façon d'identifier des requêtes similaires est d'utiliser la technique des co-clics. Si un internaute clique sur un résultat (page P) pour une requête A, et qu'il clique aussi sur cette même page P pour une autre requête B, alors la requête B est similaire à la requête A. Par exemple, si une page est cliquée dans les résultats aussi bien pour la recherche "voitures à vendre" que pour "voitures d'occasion", alors les requêtes sont similaires.
A vous de réfléchir aux implications en termes de contenu sur vos pages...
Voici le synoptique du système décrit dans le brevet :
Références du brevet : "Co-click based similarity score of queries and keywords" inventé par Henrik Jacobsson et Diego Federici, déposé le 05/01/2011 et obtenu le 23/06/2015 sous le n° 9,064,007 USPTO.
Source : USPTO
Si vous avez des questions, posez-les dans le forum WebRankInfo.
Si vous préférez du consulting, j'en propose sur mon site WebRankExpert.
➡️ Offre MyRankingMetrics ⬅️
pré-audit SEO gratuit avec RM Tech (+ avis d'expert)
coaching offert aux clients (avec Olivier Duffez ou Fabien Faceries)
Voir les détails ici


Génialissime ! Merci travail formidable et exceptionnel ++++
A priori, c’est déjà en fonction, notamment pour la personnalisation des requêtes.
Par contre, il y a mille et une façons de faire ce calcul, la méthode gagnante sera celle qui économise le maximum de ressources dans l'état de l'art.
Il reste tout de même que déposer un brevet sur des algos basiques, c’est gonflé, car, ici, ce n’est franchement pas compliqué à faire...
Au final c'est l'UX dans les serps qui détermine les futurs résultats.
À méditer...