Il n'y a pas que Microsoft qui travaille sur une évolution du PageRank pour tenir compte du comportement des internautes dans l'analyse du netlinking : Yahoo aussi a des idées pour améliorer le PageRank et a obtenu un brevet intitulé User Sensitive PageRank (bien avant la publication du BrowseRank).
Je vous ai résumé tout ça et donné mes idées (enfin, quelques unes, j'en garde certaines de côté...). J'espère que mon article vous sera utile ; en tout cas quand je lis le forum et discute avec les participants de mes formations, je pense que pas mal de monde devrait revoir ses stratégies de netlinking pour s'adapter aux algos actuels des moteurs :roll:
Le PageRank est dépassé ! En tout cas celui décrit dans l’article de référence rédigé par les cofondateurs de Google. Mais quelle est la formule désormais utilisée par Google ? Peut-être utilisent-ils déjà d’autres données que les liens entre pages web, par exemple des données représentant l’activité des internautes sur le web ? Microsoft a publié en juillet 2008 un article présentant leur algorithme du BrowseRank qui prétend justement surpasser le PageRank grâce à la prise en compte du temps passé sur chaque page. En fait c’est aussi une voie explorée par Yahoo, décrite dans un brevet intitulé User-sensitive pagerank, obtenu le 10 janvier 2008 chez le US Patent and Trademark Office. Explications…
Le brevet de Yahoo : User Sensitive PageRank
Le brevet a été déposé par Yahoo en juin 2006 et validé le 10 janvier 2008. Les auteurs sont Pavel Berkhin, Usama M. Fayyad, Prabhakar Raghavan et Andrew Tomkins. Le résumé du brevet est le suivant :
Techniques are described for generating an authority value of a first one of a plurality of documents. A first component of the authority value is generated with reference to outbound links associated with the first document. The outbound links enable access to a first subset of the plurality of documents. A second component of the authority value is generated with reference to a second subset of the plurality of documents. Each of the second subset of documents represents a potential starting point for a user session. A third component of the authority value is generated representing a likelihood that a user session initiated by any of a population of users will end with the first document. The first, second, and third components of the authority value are combined to generate the authority value. At least one of the first, second, and third components of the authority value is computed with reference to user data relating to at least some of the outbound links and the second subset of documents.
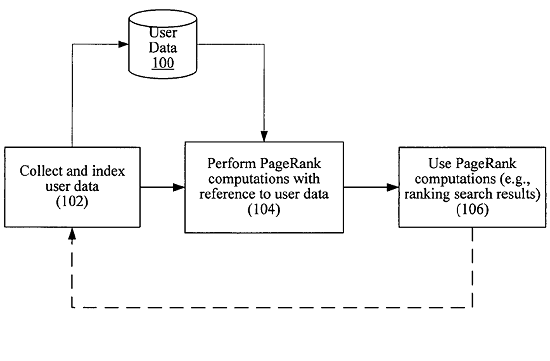
Un des schémas du brevet de Yahoo : User Sensitive PageRank
Les faiblesses de l’algorithme initial du PageRank
Les auteurs du brevet déposé par Google commencent par faire remarquer certains problèmes dans la formule initiale du PageRank :
Pour corriger les défauts listés précédemment, ce brevet propose d’utiliser des données issues de l’activité des internautes (la façon dont ils surfent sur le web) :
D’autres éléments sont abordés dans ce brevet, notamment :
Voici mes premières conclusions :
Pour en savoir plus
Je vous ai résumé tout ça et donné mes idées (enfin, quelques unes, j'en garde certaines de côté...). J'espère que mon article vous sera utile ; en tout cas quand je lis le forum et discute avec les participants de mes formations, je pense que pas mal de monde devrait revoir ses stratégies de netlinking pour s'adapter aux algos actuels des moteurs :roll:
Le PageRank est dépassé ! En tout cas celui décrit dans l’article de référence rédigé par les cofondateurs de Google. Mais quelle est la formule désormais utilisée par Google ? Peut-être utilisent-ils déjà d’autres données que les liens entre pages web, par exemple des données représentant l’activité des internautes sur le web ? Microsoft a publié en juillet 2008 un article présentant leur algorithme du BrowseRank qui prétend justement surpasser le PageRank grâce à la prise en compte du temps passé sur chaque page. En fait c’est aussi une voie explorée par Yahoo, décrite dans un brevet intitulé User-sensitive pagerank, obtenu le 10 janvier 2008 chez le US Patent and Trademark Office. Explications…
Le brevet de Yahoo : User Sensitive PageRank
Le brevet a été déposé par Yahoo en juin 2006 et validé le 10 janvier 2008. Les auteurs sont Pavel Berkhin, Usama M. Fayyad, Prabhakar Raghavan et Andrew Tomkins. Le résumé du brevet est le suivant :
Techniques are described for generating an authority value of a first one of a plurality of documents. A first component of the authority value is generated with reference to outbound links associated with the first document. The outbound links enable access to a first subset of the plurality of documents. A second component of the authority value is generated with reference to a second subset of the plurality of documents. Each of the second subset of documents represents a potential starting point for a user session. A third component of the authority value is generated representing a likelihood that a user session initiated by any of a population of users will end with the first document. The first, second, and third components of the authority value are combined to generate the authority value. At least one of the first, second, and third components of the authority value is computed with reference to user data relating to at least some of the outbound links and the second subset of documents.
Un des schémas du brevet de Yahoo : User Sensitive PageRank
Les faiblesses de l’algorithme initial du PageRank
Les auteurs du brevet déposé par Google commencent par faire remarquer certains problèmes dans la formule initiale du PageRank :
- Tous les liens ne se valent pas et ne devraient pas compter autant : par exemple les liens disclaimer (mise en garde) ou ceux qui pointent vers les mentions légales (c’est pour ça que certains utilisent le nofollow sur ces liens)
- Les internautes ne choisissent pas au hasard une page web quand ils quittent un site : dans la formule initiale du PageRank, il est prévu que de temps en temps, quand l’internaute en a marre du site sur lequel il est, saute aléatoirement pour aller sur une autre page du web. C’est la partie (1-d) dans la formule. Il est pourtant évident que dans ce cas, il est plus probable que l’internaute aille sur un (gros) site connu d’une page interne au fin fond d’un (petit) site perso…
- Les internautes ne choisissent pas les sites à fort TrustRank quand ils quittent un site : de la même manière, quand un internaute quitte un site pour aller sur un autre sans cliquer sur un lien, il ne va pas forcément aller sur un site à fort TrustRank. L’algorithme du TrustRank permet surtout de combattre le spamdexing mais il ne représente pas vraiment le comportement réel des internautes.
- Les pages web évoluent : une page peut changer de contenu à tout moment, par exemple si le site est racheté ou plus simplement si les objectifs de la page sont modifiés. Ces changements évoluent à des fréquences très variables selon les sites, et le PageRank devrait en tenir compte. Je précise qu’il ne faut tout de même pas oublier que le PageRank est recalculé très souvent en interne chez Google…).
Pour corriger les défauts listés précédemment, ce brevet propose d’utiliser des données issues de l’activité des internautes (la façon dont ils surfent sur le web) :
- La valeur d’un lien entrant dépend du trafic : le poids d’un backlink dans l’algorithme peut dépendre du nombre d’internautes qui l’ont suivi. Je pense donc que les liens vraiment destinés aux internautes auront beaucoup plus de poids que ceux créés spécialement pour optimiser le référencement.
- La partie téléportation dans la formule initiale (le fameux (1-d)) peut dépendre elle aussi des données sur le trafic
- Le degré de satisfaction de l’internaute pour la page en cours de consultation peut être pris en compte (Yahoo n’explique pas précisément comment l’évaluer)
D’autres éléments sont abordés dans ce brevet, notamment :
- Les données utilisateurs prises en compte dans les calculs peuvent être calculées sur un échantillon d’utilisateurs sélectionnés selon différents critères (âge, sexe, revenus, emplacement géographique, habitudes de surf, etc.). On pourrait imaginer que des valeurs différentes de ce nouveau PageRank seraient utilisées pour des internautes de régions différentes. On ne sait pas vraiment comment ces données concernant les internautes sont récoltées…
- L’algorithme pourrait se baser sur la façon dont les internautes visitent des pages de différents blocs (un bloc étant un site web, un nom d’hôte ou un nom de domaine). L’analyse de ces données de surf pourrait par exemple améliorer l’utilisation des blocs dans le calcul du PageRank
- De nos jours, le PageRank est utilisé dans l’algorithme qui sélectionne dans quel ordre il faut crawler le web (en gros, une page à fort PageRank a plus de chances d’être crawlée plus souvent). Si le PageRank tient compte de données utilisateurs, l’utilisation du PageRank dans le crawl permettra d’améliorer encore ce crawl.
Voici mes premières conclusions :
- Yahoo propose une nouvelle façon de calculer le PageRank, dans laquelle la popularité n’est pas seulement mesurée mathématiquement en termes de liens, mais aussi comme tout le monde s’y attend en termes de trafic généré par ces liens. Certes, cela peut paraître naturel de mesurer la popularité d’une page en fonction du trafic reçu en provenance des backlinks, mais réussir à le mesurer pour en tenir compte est une autre paire de manches !
- En prévoyant de tenir compte du trafic généré par un backlink, ce brevet confirme ce que je conseille depuis longtemps : les liens les plus efficaces sont ceux intégrés au cœur du contenu. A l’inverse, un lien en bas de page risque de plus en plus d’être insignifiant pour le référencement.
- Si Yahoo utilise réellement un PageRank personnalisé en fonction de critères aussi spécifiques que l’âge de l’internaute, son sexe, son emplacement géographique, alors d’une part on pourra vraiment jeter à la poubelle tous les outils d’affichage du PageRank, et d’autre part il sera impossible d’analyser l’influence de ce nouveau PageRank dans le positionnement.
- Même si ce brevet est associé à Yahoo, il est évident que les ingénieurs de Google l’ont déjà testé depuis des mois. Peut-être même qu’ils exploitent déjà certaines idées décrites ici…
Pour en savoir plus
")

")
