Jeff Dean, ingénieur chez Google, a donné une conférence le 20 octobre dans l'Université de Washington. Au cours de cette conférence, il a abordé plusieurs thèmes axés sur l'infrastructure technique de Google
Lecteur vidéo
00:00
58:31
Sur l'ensemble des 4 milliards de pages, la taille moyenne est de 10 Ko. Cela signifie que Google doit gérer une quantité de données gigantesque, de l'ordre de plusieurs dizaines de téra octets (environ 40 000 Go)
Google récupère énormément de données pour mieux analyser l'expérience utilisateur, qu'ils souhaitent évidemment toujours améliorer. Ces données sont par exemple les clics dans les pages de résultats. Google travaille actuellement sur de nouvelles interfaces utilisateur complètement différentes de l'interface actuelle...
Pour stocker les données et répondre aux requêtes, Google avait le choix entre des très gros serveurs ou un grand nombre de PC traditionnels. Voici une comparaison des coûts de deux solutions étudiées, qui explique pourquoi Google a choisi la seconde :
L'index de Google est découpé en petits bouts afin qu'ils puissent être stockés sur chaque machine. Chacun de ces bouts est appelé un shard. La répartition des documents en shards se base entre autres sur le PageRank.Chaque shard est dupliqué pour être sur plusieurs machines (il y a d'autant plus de duplicatas que le PageRank est élevé).
Google accorde beaucoup d'importance au temps de réponse à chaque requête. Pour ne pas excéder 0,5 seconde, Google déploie des data centers dans le monde entier afin de rapprocher les serveurs des utilisateurs.
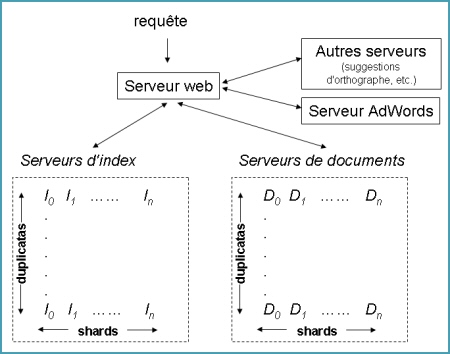
Schéma des serveurs de Google utilisés pour répondre aux requêtes
En moyenne 1000 machines sont utilisées pour chaque requête, dont le temps moyen de réponse est de 0,25 seconde. Sachant qu'il y a plus de 250 millions de requêtes par jour sur le réseau des sites de Google...
Google développe ses propres applications afin de s'adapter entièrement à ses contraintes particulières. Voici quelques exemples d'applications :
Selon le NYT, Google devrait investir 1,5 milliards de dollars en 2006 pour ses centres opérationnels et la technologie. Une grosse partie de cet investissement est consacrée à la construction d'un énorme data center en Oregon.
D'après Martin Reynolds, un analyste du Gartner Group cité par le NYT, le métier de Google est autant l'infrastucture que les moteurs de recherche. Il pense que Google est le 4ème constructeur (maker) mondial de serveurs après Dell, Hewlett-Packard et IBM !
En parallèle de la guerre visible du grand public, sur le front de la recherche web et ses dérivés, Google mène également une guerre sans merci avec Microsoft et Yahoo sur le plan des serveurs et des logiciels qui les accompagnent. Chacun estime que son architecture est optimale et que l'autre n'a pas une réelle avance technologique...
Même si Google est très secret, nous savons que plusieurs innovations ont vu le jour afin d'optimiser leur infrastructure technique, aussi bien matérielle que logicielle. MapReduce permet de découper une tâche en sous-tâches qui peuvent être traitées par des milliers de processeurs simultanément (Bill Gates prétend que son système Dryad est meilleur...). Le système de fichiers de Google, appelé Google File System, conserve des copies de données en plusieurs endroits, si bien qu'une panne d'un des serveurs ne perturbe pas l'ensemble. Google Work Queue permet d'affecter à un grand ensemble de serveurs (pool) des tâches selon les besoins, changeant sans cesse ces assignations, évitant d'avoir des serveurs coûteux dédiés à seulement certaines tâches.
Google utilise surtout des processeurs Opteron d'AMD, mais aussi des processeurs de Sun spécialement conçus pour optimiser leur consommation électrique (ce développement spécifique de Sun n'est pas étranger au fait qu'Eric Schmidt, PdG de Google, était dirigeant de Sun avant de venir chez Google). Il semblerait même que Google se prépare à créer ses propres puces électroniques !
L'article du NYT est accessible ici : page 1 / page 2
Via Google Blogoscoped
Infrastructure technique de Google en 2004
Voici quelques points abordés par Jeff Dean, fournis ici un peu en vrac... Notez que vous pouvez également retrouver l'intégralité de la conférence sous forme de vidéo (environ 1h, en anglais).Lecteur vidéo
00:00
58:31
Sur l'ensemble des 4 milliards de pages, la taille moyenne est de 10 Ko. Cela signifie que Google doit gérer une quantité de données gigantesque, de l'ordre de plusieurs dizaines de téra octets (environ 40 000 Go)
Google récupère énormément de données pour mieux analyser l'expérience utilisateur, qu'ils souhaitent évidemment toujours améliorer. Ces données sont par exemple les clics dans les pages de résultats. Google travaille actuellement sur de nouvelles interfaces utilisateur complètement différentes de l'interface actuelle...
Pour stocker les données et répondre aux requêtes, Google avait le choix entre des très gros serveurs ou un grand nombre de PC traditionnels. Voici une comparaison des coûts de deux solutions étudiées, qui explique pourquoi Google a choisi la seconde :
- Serveur IBM eServer xSeries 440
- 8 processeurs Xeon de 2 GHz
- 65 Go de RAM
- 8 To de disque
- 758 000 $
- Rack de 88 machines
- 176 processeurs Xeon de 2 GHz (88 x 2)
- 176 Go de RAM (88 x 2)
- 7 To de disque
- 278 000 $
L'index de Google est découpé en petits bouts afin qu'ils puissent être stockés sur chaque machine. Chacun de ces bouts est appelé un shard. La répartition des documents en shards se base entre autres sur le PageRank.Chaque shard est dupliqué pour être sur plusieurs machines (il y a d'autant plus de duplicatas que le PageRank est élevé).
Google accorde beaucoup d'importance au temps de réponse à chaque requête. Pour ne pas excéder 0,5 seconde, Google déploie des data centers dans le monde entier afin de rapprocher les serveurs des utilisateurs.
Schéma des serveurs de Google utilisés pour répondre aux requêtes
En moyenne 1000 machines sont utilisées pour chaque requête, dont le temps moyen de réponse est de 0,25 seconde. Sachant qu'il y a plus de 250 millions de requêtes par jour sur le réseau des sites de Google...
Google développe ses propres applications afin de s'adapter entièrement à ses contraintes particulières. Voici quelques exemples d'applications :
- Google File System (GFS) : pour le stockage. Gestion de plusieurs Po (1 Peta octets = 1024 Tera octets = 1 048 576 Giga octets). Les performance sont de 2 Go/s en lecture et écriture malgré les pannes
- Global Work Queue (GWQ) : plannificateur de tâches
- MapReduce : système simplifié de traitement de données à grande échelle, tolérant aux pannes
Infrastructure technique de Google en 2006
Le New York Times a publié un article décrivant l'infrastructure de Google, abordant entre autres la tradition du secret des data centers, les systèmes MapReduce, Google File System et Google Work Queue. Voici un résumé en français...Selon le NYT, Google devrait investir 1,5 milliards de dollars en 2006 pour ses centres opérationnels et la technologie. Une grosse partie de cet investissement est consacrée à la construction d'un énorme data center en Oregon.
D'après Martin Reynolds, un analyste du Gartner Group cité par le NYT, le métier de Google est autant l'infrastucture que les moteurs de recherche. Il pense que Google est le 4ème constructeur (maker) mondial de serveurs après Dell, Hewlett-Packard et IBM !
En parallèle de la guerre visible du grand public, sur le front de la recherche web et ses dérivés, Google mène également une guerre sans merci avec Microsoft et Yahoo sur le plan des serveurs et des logiciels qui les accompagnent. Chacun estime que son architecture est optimale et que l'autre n'a pas une réelle avance technologique...
Même si Google est très secret, nous savons que plusieurs innovations ont vu le jour afin d'optimiser leur infrastructure technique, aussi bien matérielle que logicielle. MapReduce permet de découper une tâche en sous-tâches qui peuvent être traitées par des milliers de processeurs simultanément (Bill Gates prétend que son système Dryad est meilleur...). Le système de fichiers de Google, appelé Google File System, conserve des copies de données en plusieurs endroits, si bien qu'une panne d'un des serveurs ne perturbe pas l'ensemble. Google Work Queue permet d'affecter à un grand ensemble de serveurs (pool) des tâches selon les besoins, changeant sans cesse ces assignations, évitant d'avoir des serveurs coûteux dédiés à seulement certaines tâches.
Google utilise surtout des processeurs Opteron d'AMD, mais aussi des processeurs de Sun spécialement conçus pour optimiser leur consommation électrique (ce développement spécifique de Sun n'est pas étranger au fait qu'Eric Schmidt, PdG de Google, était dirigeant de Sun avant de venir chez Google). Il semblerait même que Google se prépare à créer ses propres puces électroniques !
L'article du NYT est accessible ici : page 1 / page 2
Via Google Blogoscoped
")
 Sinon c'est marrant dans ma boite on a fait le même calcul que google il y a quelques mois (mais pour faire du calcul par éléments finis), entre un serveur et un cluster de PC la différence de tarif était d'un facteur 5 même si ca demande du boulot et de la place supplémentaire, le boss n'a pas hésité longtemps, hop un cluster de 64 machines (des p4 2Ghz et 1Go de ram), il marche super bien d'ailleurs.
Sinon c'est marrant dans ma boite on a fait le même calcul que google il y a quelques mois (mais pour faire du calcul par éléments finis), entre un serveur et un cluster de PC la différence de tarif était d'un facteur 5 même si ca demande du boulot et de la place supplémentaire, le boss n'a pas hésité longtemps, hop un cluster de 64 machines (des p4 2Ghz et 1Go de ram), il marche super bien d'ailleurs. ")
